The Hard Truth About Self-Hosting: Why My "ChatGPT Killer" Failed (And What I Learned)
I tried to replace ChatGPT with a self-hosted local LLM and n8n. Here is why it failed, the technical limitations I faced, and the reality of local AI privacy.

Last week, I shared a major update on LinkedIn regarding my shift away from commercial AI tools. I officially canceled my ChatGPT subscription to move toward a self-hosted ecosystem using local Large Language Models (LLMs) and tools like Gemini.
On paper, the plan was perfect: regain control of my data, stop paying subscription fees, and build a custom AI tailored exactly to my workflow. If you've seen the hype on Twitter or YouTube, you might assume setting up a local LLM is a plug-and-play solution that rivals the big players like OpenAI or Anthropic.
I'm here to write the article I wish I had read a month ago: That is not the case.
Here is the story of how I tried to build a "Super App," why it failed, and the realistic role of local AI in 2026.
The Vision: A Private "Second Brain"
My goal was ambitious but, I thought, achievable. I wanted to build an application that functioned as a hybrid of ChatGPT and Notion.
I didn't just want a chatbot; I wanted an Agent.
I envisioned a dashboard where I could store my capstone research, brand marketing notes, and project data. The AI would live on top of this database, allowing me to query my own information and—crucially—generate tasks and execute actions based on that data.
The Reality Check: The "Internet" Problem
The biggest disadvantage of a self-hosted LLM is one that is easily overlooked until you are staring at a terminal window: By itself, a local LLM is disconnected.
When you use ChatGPT, you aren't just using a model; you are using a massive infrastructure that includes Bing search, web browsing, and Python execution environments. When you run a model like Llama 3 or Mistral locally, you are essentially locking a genius in a windowless room. It can answer questions based on what it was trained on, but it cannot "look things up."
The Integration Nightmare (Enter n8n)
To solve the connectivity issue, I turned to n8n, a workflow automation tool. My theory was simple: I would use n8n to act as the bridge between my local LLM and the internet.
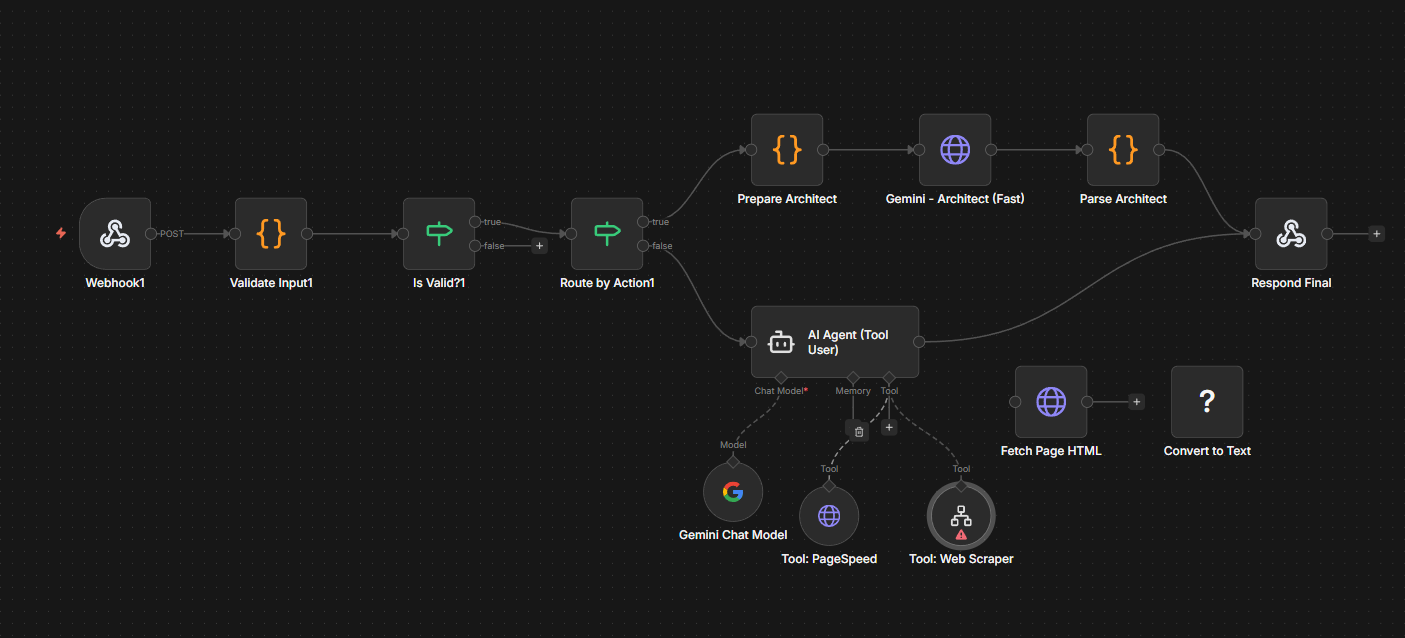
The Plan: If I asked the AI a current events question, n8n would intercept the request, scrape the web, feed the context back to the LLM, and generate an answer.
The Result: A laundry list of bugs.
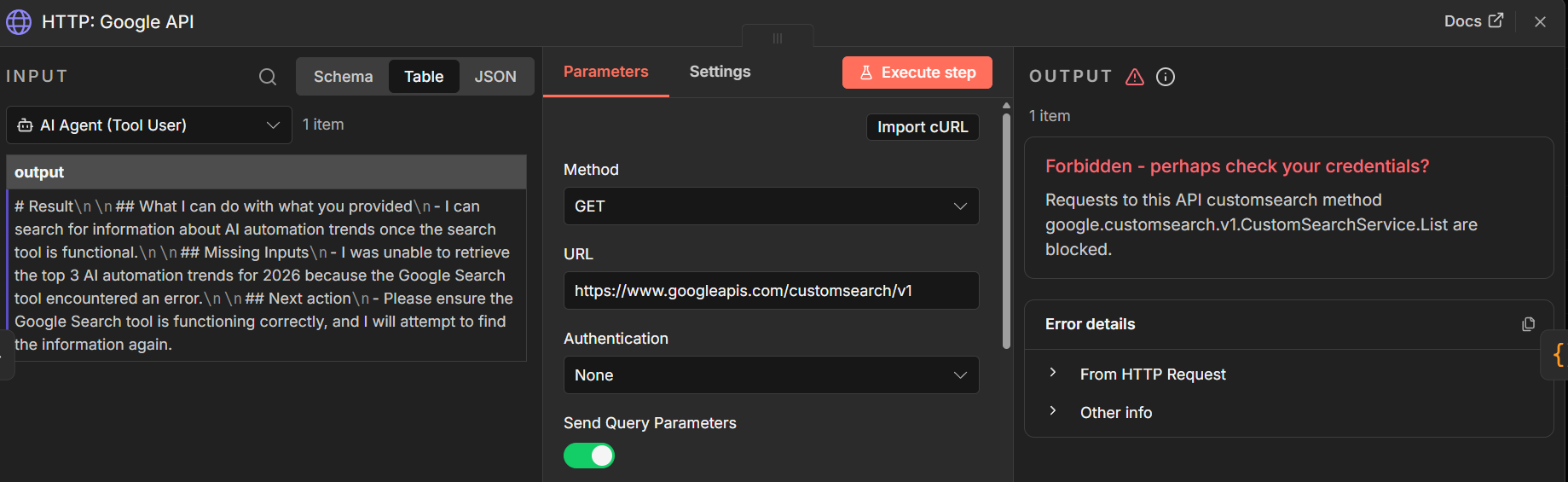
I spent days struggling to get the LLM and n8n to talk to each other reliably. I encountered timeout errors, hallucinated data formats, and connection refusals.
I realized I had bitten off more than I could chew. There is a reason why applications like Perplexity or ChatGPT are proprietary and expensive—integrating real-time web search with LLM logic is incredibly complex. The more features I tried to jam into my custom build, the more fragile the system became.
The Pivot: Synthesis vs. Discovery
Through this failure, I learned a valuable lesson about where local AI actually shines. It comes down to Synthesis vs. Discovery.
Discovery (The Weakness): If you want an AI to research new topics, find the latest news, or scrape websites, self-hosting is a path of high resistance. It requires complex tooling, proxies, and constant maintenance.
Synthesis (The Strength):Where local LLMs dominate is in processing information you already have. If you feed a local model 50 PDFs of research papers or your entire semester's notes, it can summarize, reformat, and analyze that data faster and more privately than any cloud tool.
The Privacy Trade-Off
So, is self-hosting worth it?
If you are privacy-conscious, yes. Running queries on a local LLM is the only way to ensure 100% data sovereignty. You don't have to worry about your capstone research or business ideas being used to train the next version of GPT.
But that privacy comes with a cost: Sweat Equity.

Related Article
Why I'm Moving Away from ChatGPT in 2026 (And You Should Too)
OpenAI's rev share model, intrusive ads, and eroding trust have made 2026 the year to move on.
Read Now →Conclusion
I'm still on the road to a fully self-hosted workflow, but I've adjusted my expectations. I am no longer trying to rebuild Google on my laptop.
If you are considering this path, my advice is to use interfaces like Open WebUI to interact with your models, but limit your scope. Use local AI to organize and interact with your existing knowledge base—not as a replacement for a search engine.
I'll be back with more updates as I refine this stack (and hopefully fix a few more bugs).
Frequently Asked Questions
What is the main disadvantage of self-hosted LLMs?
Self-hosted LLMs are disconnected from the internet. Unlike ChatGPT, which includes Bing search, web browsing, and execution environments, local models like Llama 3 or Mistral cannot look things up in real time.
Where do local LLMs excel compared to cloud AI?
Local LLMs excel at synthesis—processing information you already have. They can summarize, reformat, and analyze PDFs, notes, or research papers faster and more privately than cloud tools. They struggle with discovery tasks like researching new topics or scraping the web.
Is self-hosting worth it for privacy?
Yes. Running queries on a local LLM ensures 100% data sovereignty. Your research and business ideas are never used to train the next GPT. The tradeoff is sweat equity—complex tooling, proxies, and maintenance.
Related Reading
Explore more on self-hosting, n8n, and AI workflows:
- Why I'm Moving Away from ChatGPT in 2026 (And You Should Too)
- The Ultimate Guide to Zapier GPT Integrations (and Why You Should Stop Using Them)
- I Fired Myself as a Social Media Manager
- How to Use Cursor AI in 2026: The Zero-BS Beginner's Guide
- How to Use Gemini Notebooks in 2026 (The Context Bottleneck is Solved)
Ready to build your content engine?
Get a free 20-minute audit of your current processes and discover which workflows you can automate today.